The constraint architecture solved the quality problem, Scale was a different problem.
Producing content across 20+ markets without losing consistency required more than better prompts and tighter rules. It required a production system and the first attempt at building one revealed the next problem.
The Master GPT That Did Not Work
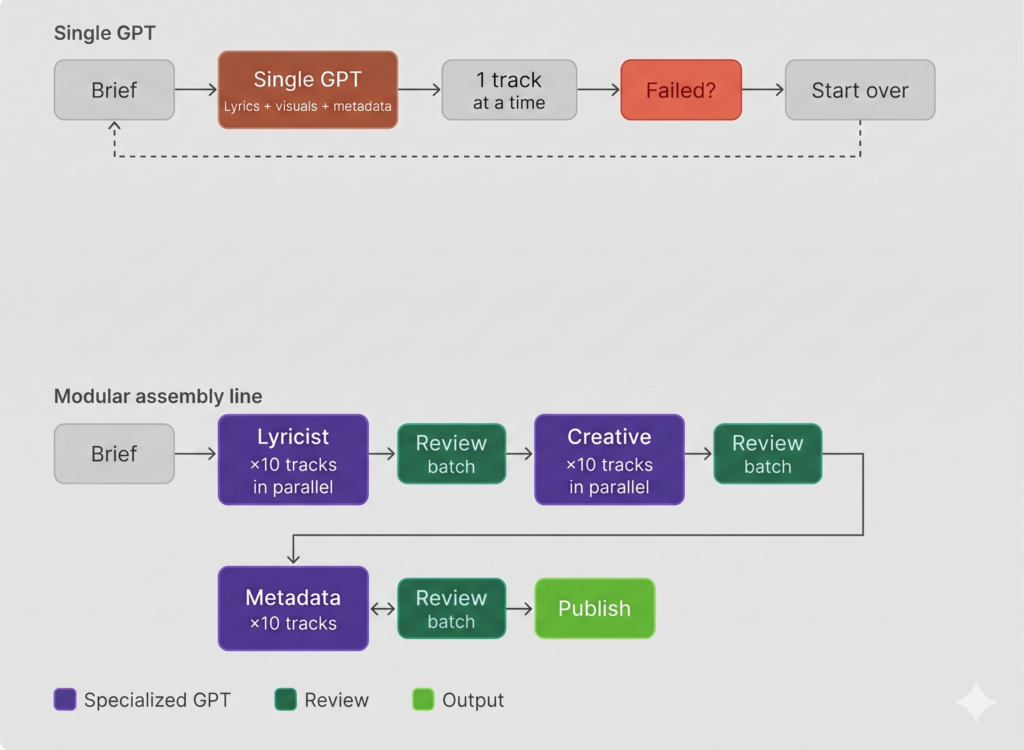
My first instinct was to build one GPT that handled everything: lyrics, video prompts, SEO metadata. Feed it a brief, get a finished asset back. It had a lot of problems.
When a single model is asked to context-switch between writing genre-specific lyrics, describing visual scenes, and formatting search metadata, it gets confused and starts guessing. The lyrics would be strong but the video prompt would drift. Fix the metadata and the lyrics would break. Every adjustment destabilized something else, and the more tasks the model held at once, the more quality degraded across all of them.
The first assembly prompt had another problem. It was limited to one song at a time, so if the track did not land, the entire creative output went with it.
The Assembly Line
The solution was splitting the work across three specialized GPTs.
The Lyricist writes lyrics. The Creative generates image, video prompts and visual direction. The Metadata GPT handles titles, descriptions, and tags. Each does one job and none of them interfere with each other.
Worth being clear about what that actually means in practice. These GPTs do not make autonomous decisions or hand off work to each other independently. I decide what gets fed in, review what comes out, and make changes before sending anything back for reprocessing. Not every output is usable, but having the GPTs produce multiple tracks simultaneously means I can QA a batch quickly, flag what needs fixing, and run it again. The speed is what makes that practical. The “Human in the loop” is by design.
That separation made batching possible. Ten songs could run through the Lyricist simultaneously, then feed into the Creative GPT all at once, and the production volume that a single master GPT could not handle became manageable across a modular system.
Quality Control
Three layers of quality control were built into the pipeline.
Layer one: the QA GPT
The first layer was a dedicated QA GPT with one job: audit Lyricist outputs and flag forced slang, brand usage, mismatched references, and instrumentation errors. An automated check between generation and publishing to catch errors before they reach an audience.
| Brand Usage -remove and change lyrics | Clean Lyrics |
| En WhatsApp no hay señal, pero en Insta hay carnaval… /// [0:14 Silencio Repentino] /// (¡Qué descaro!) /// [Drop: Bombo pesado de doble golpe] /// [Verso 1: Flow rítmico pop rápido y sarcástico] /// El martes llorabas miseria pidiendo un favor /// pasaste tu código triste por el mostrador /// (¡Eso!) | [Intro: Modern Pop Synth + Heavy Brass] /// Me dijiste que no había ni un peso /// [0:14 Sudden Silence] /// (¡Qué falso!) /// [Drop: Heavy double-beat bass + Aggressive Brass] /// [Verse 1: Fast rhythmic pop flow] /// Lloras por la deuda de la otra semana /// dices que la calle no te da la gana /// |
Layer two: manual review
The second layer was a manual review. Because the modular system standardized outputs., anything off stood out immediately. The consistency also made pattern recognition practical. Ten consecutive tracks carrying the same slang misuse. A genre drift repeating across the same subgenre. When a pattern emerged, the fix went directly back into the GPT instructions rather than being corrected track by track. Identifying systematic errors and updating the instructions accordingly is what kept the system improving rather than just running.
Sample Prompt change:
Hard Negatives: Strictly prohibit the use of: Romper el bajo, Rompiendo, Mover la cadera, Toca el cielo, Retumba el suelo, Clika, Flacoso.
Zero Meta-Lyrics: The AI is forbidden from referencing the song, the genre, or the listener’s reaction (e.g., NO “esta cumbia me motiva”, “suena la clave”, “báilalo así”).
Layer three: the audience
Comments are the third layer and the most direct signal of what is actually working.
Some songs get a wall of emojis and some get detailed feedback. I respond to everything. When a listener is genuinely curious about a sound, tells me what they like, and points me toward examples, I make a track based on that and send it back. If it lands, a new fan. If someone just complains without engaging, a polite redirect to other videos on the channel.
The AI made the execution possible because without the GPT pipeline, responding to audience requests at this pace would not be feasible. The comments close the loop between what the system produces and what the audience actually wants.
One listener left a comment on a Champeta track saying the fusion sounded elegant but asking if we could go older, back to the soukous style of the 80s and 90s. That is a specific enough request to act on. A 90s Champeta track went into the pipeline that week. When it came back out the listener said the guitar sounded spectacular.
The Thumbnail Problem
One problem that took longer to solve was getting AI to format text correctly on thumbnail images. Early iterations failed consistently. The workaround was copying successful prompts into new chats to show the model what had worked, then running it again. It helped but did not fully solve it.
The breakthrough came from splitting the work across two models. One to generate, one to debug. When an output failed, I copied the result and the reasoning log into a second model and explained the problem. The auditing model would identify exactly where the first model had gone wrong and return a refined prompt targeting that specific failure. Different models have different strengths. Using them in combination rather than asking one model to do everything became a standard part of the workflow.
The Knowledge Problem
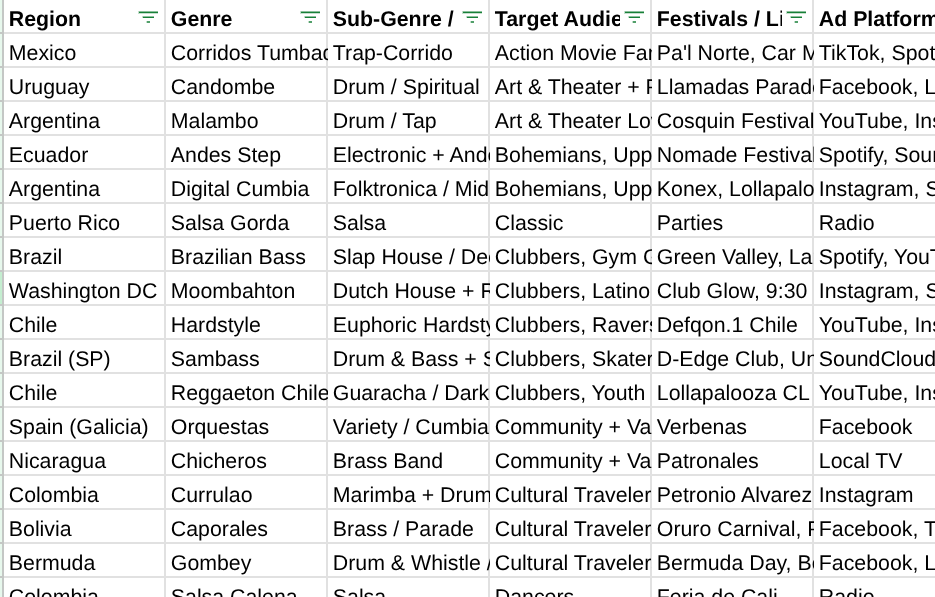
The architecture controlled the process but it could not fix what the model did not know. The Master Prompt defined creative boundaries for each genre but it needed reliable source material to draw from. Without it, the models defaulted to the most common sounds in their training data and occasionally filled gaps with plausible but incorrect details. Building a proprietary Genre Database and feeding it directly into the GPTs addressed that directly.
What the Genre Database contains
The Genre Database maps hundreds of LatAm music genres and subgenres across every relevant dimension: instrumentation, regional context, target audience, visual aesthetic, and market demand signals by country. When the GPT generates output for a Bolivian Caporales track, it references a structured dataset specifying the bells on boots, the brass arrangements, the high-altitude visual palette, and the audience profile. The same applies across every genre in the pipeline.
The Human in the Loop
The system does not run itself. Content decisions, creative direction, and campaign management all require someone watching the data and acting on it. AI handled the production volume. Writing lyrics, generating visuals, producing metadata, auditing outputs. Tasks that would have taken a team working sequentially could be batched and run in parallel. That is what made it possible to run 20+ markets, hundreds of assets, and a live advertising campaign as a one-person operation. The automation is real but so is the ongoing human review that keeps it on track.
Reading the Data
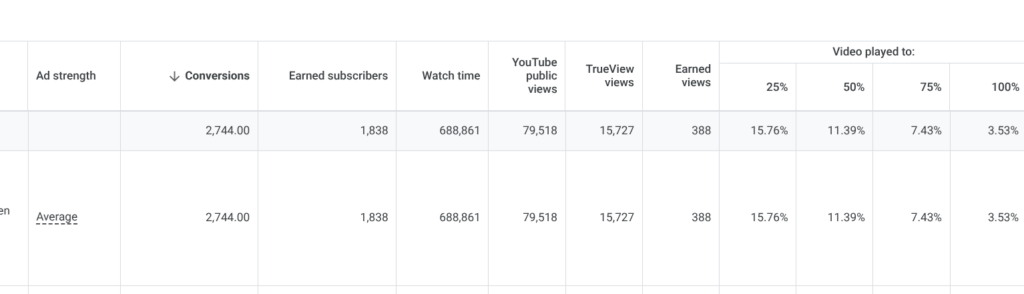
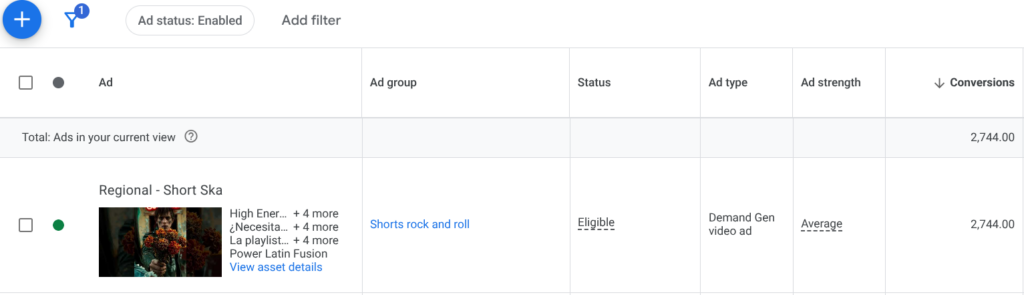
On the advertising side the focus is on maximizing conversions and minimizing CPA. But watch time determines where to place the bets. A campaign getting strong conversions but low watch time gets a lower bid and the funds move elsewhere. On the YouTube side the focus is on which videos are generating the most watch hours and how that tracks against where conversions are coming from. The two tend to align. Earned subscribers, people who subscribe without being directly paid for, create compounding watch time without additional spend and are tracked separately from paid acquisitions.
The system held because the architecture was modular, the knowledge base was specific, and the human stayed in the loop throughout. The content pipeline was ready for a real market test.
| Ad Stats
|
 |
| AVD by Country |
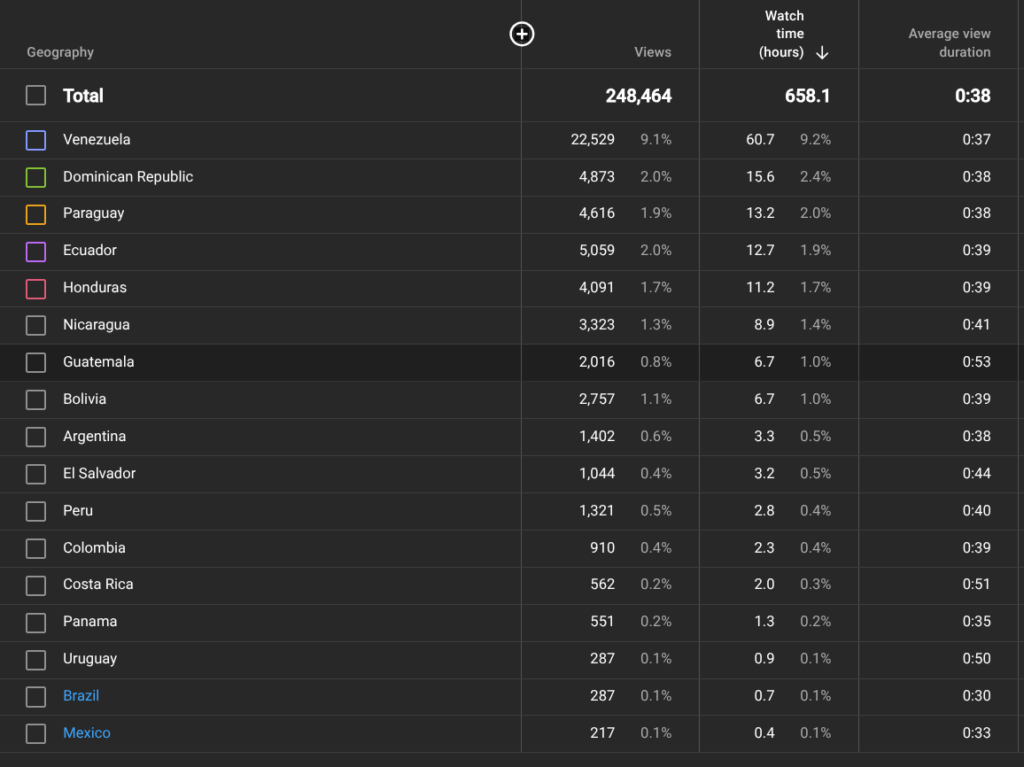 |
| Ad Group Reorganization by AVD |
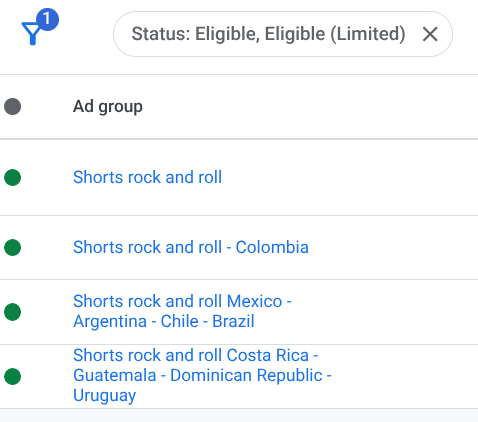
Post 3 covers what the data showed when it ran.