It started with curiosity
A conversation about AI-generated content on LinkedIn raised a question: could AI produce content that resonates with people? A friend and I were talking about AI-written thought leadership, specifically how easy it was to spot via the telltale signs: phrases like “is not this but,” “the X that changes everything,” “the answer surprised me.” We landed on an idea: create a product, use the ad copies as the test, and measure performance in engagement and sales. Two birds, one stone.
We did not agree on the product. But the original question stuck. Could AI content actually resonate with a real audience? I still wanted to find out. Looking for a lower-lift vehicle, I considered everything from ebooks to templates, and ultimately landed on music.
Why Music
Music was the practical choice.
Most products require scoping, building, and testing before we can test them. With Suno and Veo, a finished track with visuals can be produced quickly, which meant new content variations could be tested quickly without a significant budget behind them. Basically, I judged the video’s performance the same way I would judge ad copy: engagement, conversions, and cost.
Music has established demand. Listeners have clear tastes, from Reggaeton to Rock and Roll, and platforms have the targeting data to reach them. No audience education phase. No product to scope. No market to create.
Fast production plus a pre-existing addressable market made music the right place to run this experiment.
Worth noting upfront: AI-generated music is not new territory. YouTube is full of it and audiences know exactly what they are looking at. The channel was transparent about being an AI project from the start. That context matters because the results were not driven by novelty. Audiences engaged knowing what the content was.
The Test
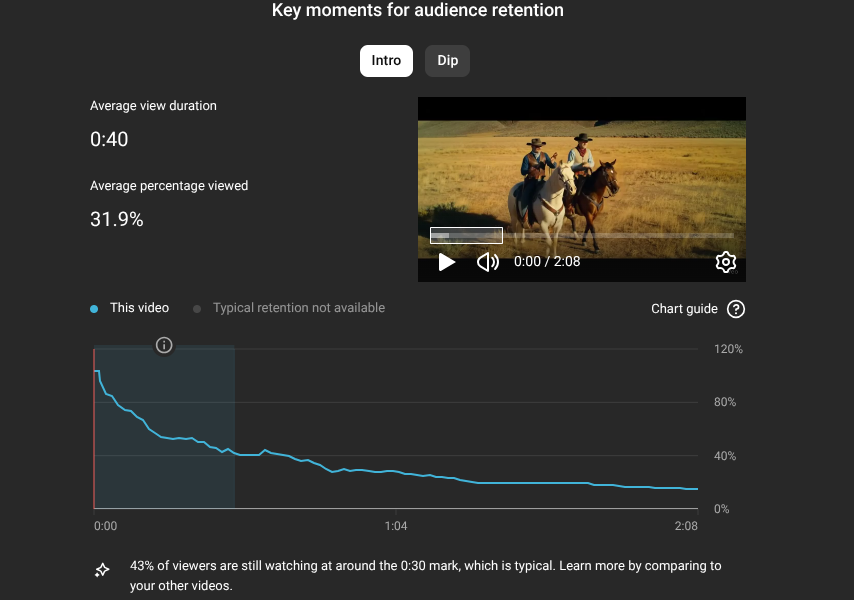
First I needed to decide what to measure. One KPI to unify paid and organic campaigns. I discarded Subscribers, CTR, CPA, and Likes. They track activity but not whether the viewer is actually engaging with the content. I landed on Average View Duration (AVD). It measures how long the video is watched, which drives total watch time, which is what YouTube rewards with recommendations and organic growth.
With the metric set, I needed a first video. I decided on a cowboy techno song. I did not feel extremely creative. Fortunately, AI came to the rescue.
The expectation for the song was something country-adjacent with electronic production. What Suno returned was a quirky track about Space Cowboys in a Technicolor prairie, fighting bad guys, visually specific and fun. The lyrics were strong enough to feed directly into Veo for the visuals, and the Space Cowboy video came together from that accident.
But the Space Cowboy worked because the output was accidentally specific. There was no way to reproduce that deliberately or predict when the next good accident would happen. That gap between an accidental output and a consistent product was the problem to solve.
From Space Cowboys to Latin Fusion
The Space Cowboy proved that specific content holds attention. The logical next step was to test whether that held at scale. Electronic music felt like the safe starting point: universal, language-agnostic, and easy to produce quickly. No language barrier, easy to iterate.
Twenty tracks across different hooks and fusions, and they all performed badly. The space was too broad and too saturated to gain traction without a significant budget behind them.
The data showed something else. Latin content, tested as part of the broader EDM experiments, was consistently outperforming every other variation on average view duration. The audience was staying longer, engaging more, and coming back.
Two things made Latin music the obvious direction. The engagement signal was already there, and CPMs across LatAm markets are significantly cheaper than in North America or Europe, which meant aggressive testing across multiple markets was possible without burning through budget. More tests, faster feedback, lower cost per data point.
AI as a Creative Partner
Creating Authentic Lyrics
Reaching 20+ markets meant the lyrics needed to sound authentic to each genre and region, including proper use of country-specific speech patterns, accents, and slang.
The first AI-assisted Latin music outputs read like corporate PR dressed up in Spanish. The lyrics did not sound like how a person speaks or sings. They lacked emotion and were oddly generic.
I also needed to mind accents in order to get authentic output. Regional accent needed to match the genre: Vallenato should have a Colombian accent, RKT an Argentinian one. It is not a hard-and-fast rule, as the genres are popular in many countries. For example, there are great Mexican Vallenato songs, but accents are an important piece of the prompt architecture.
Adding regional slang to the prompt was challenging. The model overcorrected, recycling the same five words across every genre whether the target was a Peruvian Huayno or a Mexican Sonidero. The slang overpowered the lyrics, making the output sound like someone trying really hard to be cool.
The default bias
The bias was not limited to language. Ask for something energetic and the model defaulted to Phonk, not because it was the right creative call, but because Phonk dominates global trend data. This is a well-documented behavior in large language models called training data gravity: the model defaults to whatever is statistically dominant in its training data, regardless of what the prompt asks for.
The early fix was writing prompts in Spanish. Giving the model instructions in the target language produced noticeably more authentic output than prompting in English and asking for Spanish results. I landed here by realizing that when I asked questions in Spanish, the AI responded in friendly, fluid Spanish. I tested the prompt by giving the instructions in Spanish and the lyrics improved.
That workaround became unnecessary as the models improved. Cross-language instruction handling got significantly better and English prompts started producing better native Spanish output.
The Phonk default had an unexpected result: it accidentally exposed a genuinely engaged Mexican and Argentinian Phonk audience. Rather than fighting the bias, a dedicated Phonk playlist was built around it, including regional fusions like Phonk Requinto and Phonk RKT that the system could produce consistently. Happy accidents!
Adrenalina Pura has gotten almost 30K views and over 1k likes and 50 hours of watch time.
The Instrument Problem
The language problem was visible from the first output. The instrument problem was trickier.
Genres from Colombian Vallenato to Bolivian Caporales to Argentinian Malambo use completely different instrumentation. Early prompts were loose: “create a Vallenato song about X.” That had its own problems.
Any flute instruction, regardless of how specifically the regional context was described, came back sounding like an Irish festival. The model’s training data seemed to skew heavily toward Celtic folk music and overrode everything else. The model was filling gaps with common references rather than the provided context.
The fix required removing generic instrument names from prompts entirely. Not “flute” but Quena and Zampoña playing a melancholic melody. Mexican Guitarrón instead of bass guitar. Colombian Gaitas instead of woodwind. Specificity consistently worked, but specificity alone was not enough.
The Architecture Fix
Better prompting improved outputs but did not solve all the problems. New ones surfaced after each iteration. The slang fix caused the model to overindex on slang in the lyrics, which led to a rule of no more than 5% slang in any output, with natural language as the default. Each failure pointed to a specific gap that required a specific fix. I needed to work on the architecture, not just better prompts.
The Constraint Layers
Every constraint in the architecture came directly from something that had already broken. The Phonk bias needed a banned terminology list or the model ignored the target genre entirely. The slang problem needed a hard ratio, no more than 5%, or it became the meal rather than seasoning. Emotional flatness needed an anchor, love, betrayal, hustle, joy, or the lyrics stayed inert. Instrumentation needed native-language specs or the model reached for the nearest Western equivalent. Nothing was added speculatively. Each layer was a scar from a previous failure.
Prompt Examples:
Giving the Model a Role
Instead of issuing instructions to a general-purpose tool, each GPT was configured as a Master Lyricist for a specific genre. In technical terms, this is called few-shot persona prompting: giving the model a defined role, examples of desired behavior, and boundaries that shape every output it produces. The constraints told the model what it could not do, and the role told it what it was. Together, they produced consistent, specific, repeatable output that held up against a real audience.
What This Means
The tools are accessible to everyone. Suno, Veo, and every other AI production tool in this stack can be used by anyone with an internet connection. The outputs can be fast, impressive, and occasionally surprising in the right direction. But without a control layer the results are random. Accessible tools plus the right architecture are what separates a content engine from a slot machine.
That architecture is what made everything else possible. Post 2 covers how it scaled to 20 markets running simultaneously, with consistent output, across genres that had never been touched by this kind of production system before.